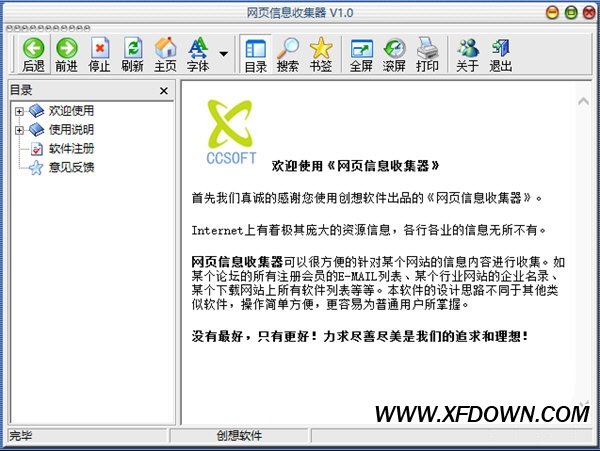
大小:3.22MB / 语言:简体中文
大小:127.35 MB / 语言:简体中文
大小:73.48MB / 语言:简体中文
大小:22MB / 语言:简体中文
大小:93 MB / 语言:简体中文
大小:837KB / 语言:简体中文
大小:45.07MB / 语言:简体中文
大小:2.24MB / 语言:简体中文
大小:71.16MB / 语言:简体中文
大小:51.39 MB / 语言:简体中文